Recommendations
Each of the 11 Regional Associations (RAs), as part of NOAA-IOOS, operate independent infrastructure to process, store, and serve their data. The RAs mainly operate Traditional On-Premises and Infrastructure-as-a-Service (such as VMWare) configurations. Several RAs run services in the cloud, and the cloud providers used vary.
It is important to ensure that the RAs are able to operate independently and have the resources they need. The cloud is a centralized IT infrastructure that is meant to be accessed from anywhere in the world and maintains a high operational posture. IOOS as a whole can adopt cloud infrastructure to reduce the burden of maintaining on-premises systems and shift those resources toward creating services and data products for downstream customers. Much of the infrastructure and plumbing can be shared across RAs, but the key differentiator will be providing cloud-optimized data access to the important data products produced by each RA.
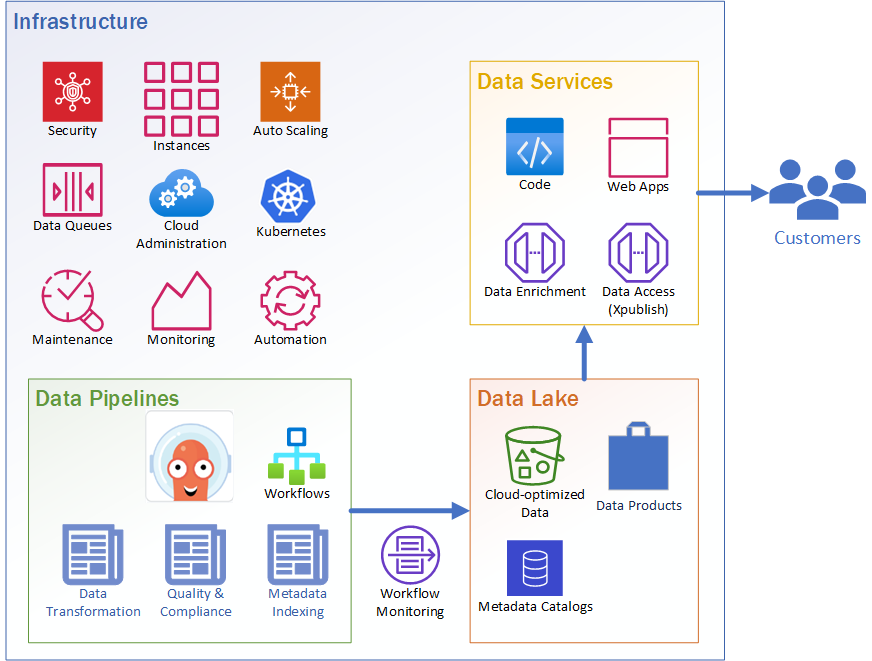
The following diagram shows the recommended overall system architecture.
Data Storage
One of the primary challenges experienced today is being able to access IOOS data in a consistent manner. The prototypes we’ve developed have demonstrated that cloud-optimized data provides significantly more efficient access to data than existing services such as THREDDS and ERDDAP. The scalable nature of cloud storage, in terms of both storage and access, is a key differentiator from traditional on-premises storage. The cloud can be used as a central repository that many organizations can access from anywhere in the world. This pattern of maintaining a central data repository for all kinds of data is what’s referred to as a “Data Lake.”
From an IT operations and maintenance perspective, the costs of provisioning, configuring, and monitoring Network File Systems (NFS) are much higher than the cloud provider’s fees for storage at $0.01 per GB. This is because the cloud provider is responsible for the entire infrastructure, including the operating system, storage, and networking. The cloud provider also provides a high level of security and encryption. At NOAA, use of the NOAA Open Data Dissemination (NODD) program even further reduces the cost of storage and egress by making the data completely free.
Cloud Optimization Workflows
Our prototypes rely on cloud-optimized data and require a workflow to translate the original data into cloud-optimized formats. Forecast data needs to be continuously optimized as new forecasts are produced. This optimization process can run centralized or decentralized, but there is potential for more data challenges in a decentralized approach. A centralized approach makes data standards and consistency easier to enforce. A decentralized approach would enable the RAs to have more control over the entire ingest process, but would require more work to maintain consistency across the RAs. We recommend that the infrastructure be centrally managed to reduce overall systems management costs, but provide RAs the tools necessary to manage their own data within a common framework.
Serving Data
The data lake is a collection of raw data files that are stored in a cloud-optimized format. This data can be accessed directly by anyone, but dealing with scientific data is complicated. Experts in data processing may want to build their own pipelines to access the data, but the majority of users and customers likely want specific information from the data. We’ve identified several common access patterns among data consumers and have coded those queries into services. This creates a layer of abstraction between the raw data and the data consumers to provide more consistency and ease of use. In addition, the complex engineering required to scale and operate those services is managed in a single service layer rather than being spread across many different systems.
Another challenge being solved is providing consistency in the data itself. The modeling community provides data in a variety of formats, coordinate systems, time steps, and naming conventions. Moving to a standard platform reduces the friction of interpreting results across datasets and providers. It empowers data consumers to focus more on analysis and less on data wrangling.
The shift from providing raw data as products to services as products allows the product owners to interpret the data as they understand it, rather than leaving that interpretation up to a 3rd party. In addition, when the raw data products change, it is up to the product owner to update the services to reflect those changes. This reduces the chance of downstream processing errors.
Services encourage innovation and scale. Unlike raw data files, there is no limit to the number of services or views of the data aside from the number of products the organization can maintain. Services can be centralized and/or distributed among organizations. One approach might be to host one large service provider for all of IOOS (standard services) and then each RA could also provide services specific to their data products. Ideally the RA services would be federated into a common service catalog to provide a single view of all possible data products.
Our cloud-native approach to building services means that there are few limitations to how the services are hosted. The services can be hosted on a single server, distributed across many servers, on a single cloud provider, or across many cloud providers. IOOS has many options on how this architecture can be implemented.